Stop Telling Your AI Agent What Not to Do
We built structured skills for our AI agent and watched performance drop by 6x. Here's what we learned.
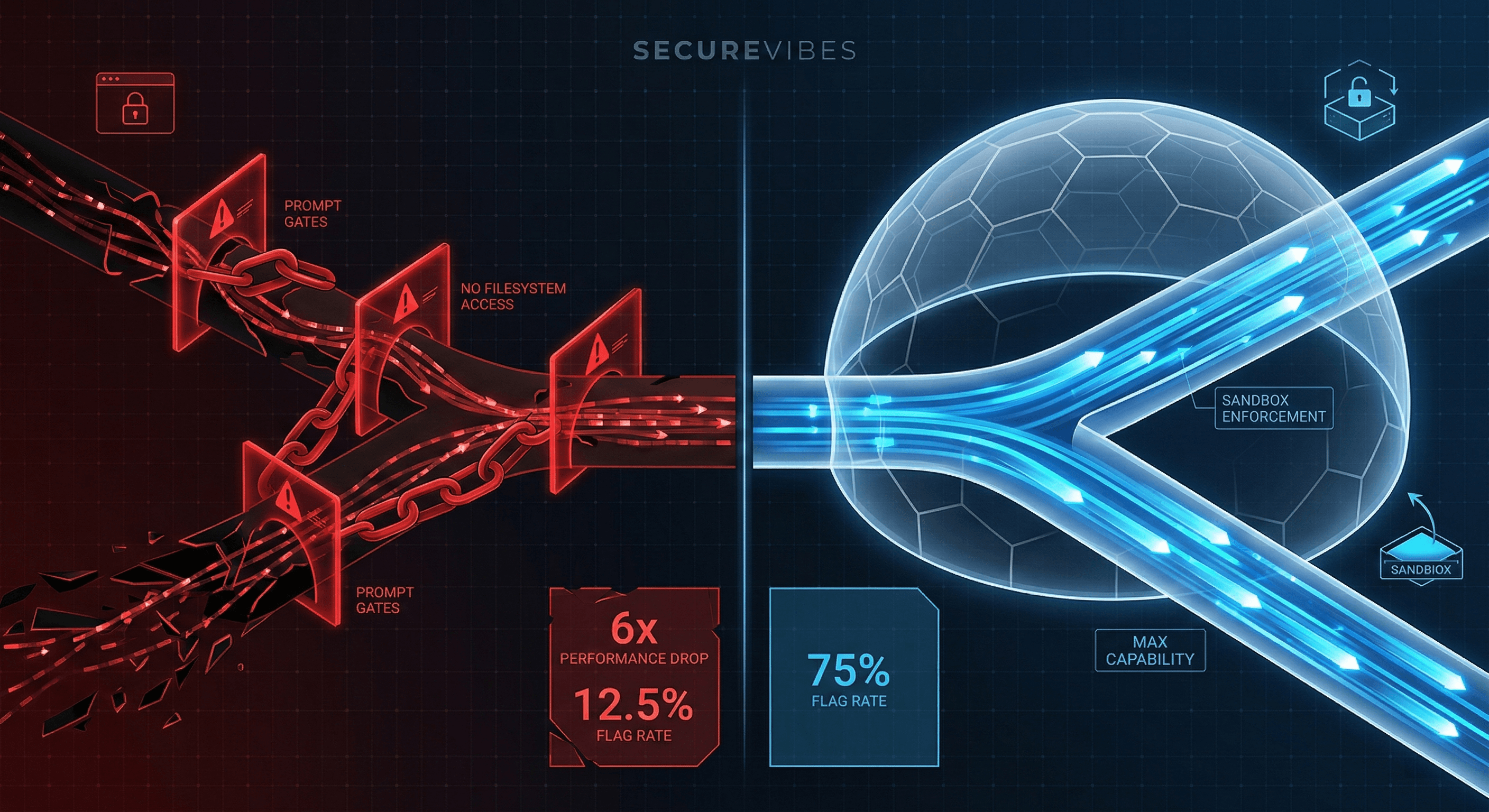
We spent weeks building structured skills for a security testing agent, watched performance drop by 6x, and realized the problem wasn't the skills. It was that we were trying to make the agent safe through prompting instead of through its environment.
This post is about a mistake we think a lot of people building agentic systems are making right now, and a better alternative that preserves agent capability while still keeping things safe.
The Mistake We Made
SecureVibes is an open-source security scanner built on Anthropic's Claude Agent SDK. One of its components is a DAST (Dynamic Application Security Testing) agent that takes vulnerabilities found during static analysis and validates them by actually attacking a running instance of the application over HTTP.
When the agent was first built with no guardrails, it was effective. It found vulnerabilities, crafted creative payloads, adapted to responses. It was also concerning. It would create files on the filesystem, try to access databases directly, modify application configuration. It behaved like an unsupervised pentester with root on the box.
There was no sandbox at the time. So we did what felt natural: we told it what not to do.
- You MUST only attempt validation when a matching skill exists
- Do NOT create arbitrary code files unless instructed by a skill
- If no applicable skill exists, mark as UNVALIDATED
We also added structured "skills" (detailed methodology files for SQL injection, XSS, command injection, etc.) and told the agent it could only test vulnerabilities when it had a matching skill loaded.
Sounds reasonable, right? Give it a rulebook and a safety net.
Then we ran benchmarks.

With all the careful constraints and skills: 12.5% flag extraction rate.
With everything removed (no skills, no gates): 75%.
The smallest model tested, Haiku, went from 0% to 100% just by removing the constraints. Zero to Hero.
The "safety" added through prompting had destroyed the agent's ability to do its job.
Wait, What Are Skills, Exactly?
Before explaining why this went wrong, let's back up. "Skills" is a specific concept in the Claude Agent SDK, and understanding what they are makes the rest of this story make more sense.
A skill is a structured markdown file (SKILL.md) that you place in your project's .claude/skills/ directory. It contains YAML frontmatter (name, description, allowed tools) and a markdown body with domain-specific methodology, examples, and instructions. At runtime, the SDK automatically discovers these files and makes them available to the model. The model then decides when to invoke a skill based on the task context.
Here's a simplified example:
---
name: sql-injection-testing
description: Validate SQL injection vulnerabilities including time-based,
error-based, and boolean-based patterns. Use when testing CWE-89.
allowed-tools: Read, Write, Bash
---
# SQL Injection Testing
## Methodology
1. Identify injectable parameters from the vulnerability report
2. Test error-based payloads first (fastest signal)
3. Fall back to time-based blind if errors suppressed
4. Attempt UNION-based extraction if column count determinable
## Example Payloads
- Error-based: ' OR 1=CONVERT(int, @@version)--
- Time-based: '; WAITFOR DELAY '0:0:5'--
We built 8 of these: SQL injection, XSS, command injection, authorization testing, XXE, SSRF, NoSQL injection, and a general injection skill for SSTI/LDAP/XPath/CRLF. Each was 250-460 lines of structured methodology with real payloads, database-specific notes, and evidence capture formats.
Where Skills Actually Help
Skills aren't inherently bad. They're genuinely valuable when they contain knowledge the model doesn't already have:
- Domain-specific knowledge — Your organization's custom authentication flow, your proprietary API conventions, your internal service mesh topology.
- Organization-specific methodology — Your compliance requirements demand specific evidence formats. Your risk scoring uses a custom rubric.
- Emerging attack patterns — A novel CVE dropped last week. A new attack technique was presented at DEF CON. The model's training data doesn't cover it yet.
- Rare or niche technologies — Testing a custom binary protocol, an obscure database engine, a proprietary messaging format.
Where Skills Don't Help (and Can Hurt)
Most of the skills we built fell into this category:
Well-documented vulnerability classes: SQL injection, XSS, command injection, IDOR. These are the OWASP Top 10. Every security tutorial, blog post, tool manual, CTF writeup, and textbook on the internet covers these. The model has ingested all of it. The 460-line SQL injection skill was essentially re-teaching Claude what it already knew, but in a more rigid format.
Standard testing methodology — PTES, the OWASP Testing Guide, NIST guidelines. These are public, well-documented frameworks. The model knows them.
Generic payload collections — Lists of XSS payloads or SQLi strings. The model has seen more of these than any single skill file could contain.
Key Question: "If Claude were given this task with no skill file, would it know how to do it?" For SQL injection testing, the answer was obviously yes. We just didn't ask.
The Specific Drawbacks We Hit
1. Context overhead that scales with skill count.
Each skill is 250-460 lines. When the model loads a skill, that's 250-460 lines of methodology competing for attention with the actual task context. For Haiku with its smaller context window, loading one skill consumed a significant fraction of its effective workspace.
2. Recipe-following replaces adaptive reasoning.
When a skill says "Step 1: Test error-based payloads. Step 2: Test time-based blind. Step 3: Try UNION-based extraction," the model follows the recipe. It stops observing, adapting, and improvising.
3. The gating trap is almost inevitable.
The moment you have skills, the natural instinct is to tie them to execution: "use the matching skill for each vulnerability type." From there, it's a short slide to "only test when a skill exists." The model's own expertise gets locked behind a skill-existence check.
4. Skills create a false sense of coverage.
Having a SQL injection skill makes you think "SQL injection is covered." But the skill only covers the patterns you thought to include. The model, unconstrained, might try approaches the skill author never considered.
Why We Reach for Prompt Constraints
When you give an AI agent tools like Bash access, file system writes, and HTTP requests, and it starts doing things you didn't expect, the natural reaction is to tell it to stop.
The problem is that LLMs process constraints differently than humans do.
When you tell a human "don't access the database directly," they understand the intent and can make judgment calls at the boundary. When you tell an LLM the same thing, you're consuming context tokens, shaping its attention distribution, and closing off entire branches of its reasoning tree. The model doesn't understand your intent. It pattern-matches against the constraint and avoids anything that looks like it might violate the rule.
You wanted a guardrail. You built a straitjacket.
The Capability Tax of Prompt Safety
1. Context gets eaten alive. Every "don't do X" instruction is tokens the model has to hold in working memory.
2. The model's decision tree narrows. Without constraints: "What's the most effective way to test it?" With constraints: "Is there a skill for this CWE? Yes? Follow steps 1-7."
The first is an agent. The second is a checklist executor.
3. Creative problem-solving dies. The unconstrained agent would chain multiple requests, create ephemeral scripts, adapt to responses. None of that happened with skills loaded.
4. Smaller models get hit harder. Haiku went from 0% to 100% flag extraction when constraints were removed. Every instruction token is proportionally more expensive in a smaller context window.
The Alternative: Let Them Loose in a Sandbox
The fix isn't "remove all safety." The fix is moving safety to the right layer.
Instead of telling the agent what not to do (prompt-level), you put it in an environment where it can't do harmful things regardless of what it tries (environment-level).
A sandboxed agent doesn't know it's sandboxed. It doesn't waste context processing "am I allowed to do this?" checks. It just works, and the environment quietly prevents anything harmful.
The Layered Architecture
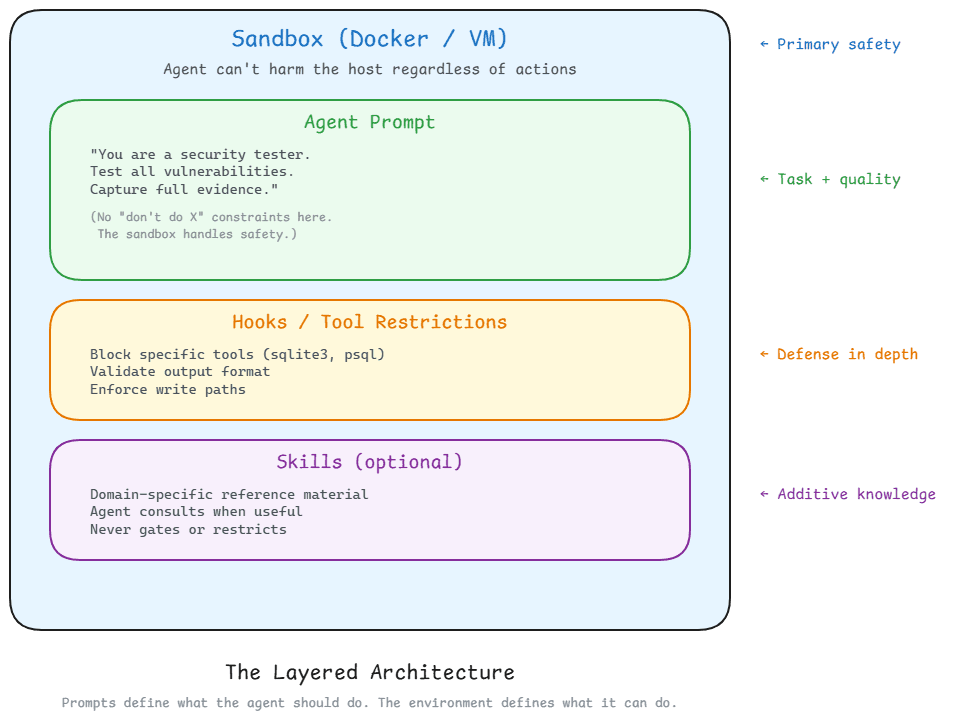
LAYER 1: Sandbox (Docker / VM) — Primary safety. Agent can't harm the host regardless of actions.
LAYER 2: Agent Prompt — Task + quality. "You are a security tester. Test all vulnerabilities. Capture full evidence." No "don't do X" constraints.
LAYER 3: Hooks / Tool Restrictions — Defense in depth. Block specific tools. Validate output format. Enforce write paths.
LAYER 4: Skills (optional) — Additive knowledge. Domain-specific reference material the agent consults when useful. Never gates or restricts.
Prompts define what the agent should do. The environment defines what it can do. Mixing these up — using prompts for safety — is where things go wrong.
What We'd Do Differently
Starting over with any agentic project:
- Build the agent with zero prompt constraints. Let it do its job. See what it naturally gravitates toward.
- Identify the dangerous behaviors. Not hypothetical dangers — actual behaviors you observed.
- For each dangerous behavior, ask: can the environment prevent this? If yes → sandbox it. If no → add a programmatic gate.
- Only after exhausting environment and programmatic options, consider prompt constraints. And keep them minimal.
- Benchmark everything. Run the same test with and without each constraint layer. If a constraint doesn't measurably improve safety or output quality, remove it.
The Uncomfortable Truth
The model already knows how to do most of what we were trying to teach it through skills. SQL injection testing methodology? XSS payload crafting? OWASP Top 10? Deeply familiar with all of it.
The litmus test: Does this contain knowledge the model genuinely doesn't have? If the answer is no, you're trading context space for redundancy. And as our benchmarks showed, that trade can be far more expensive than you'd expect.
We're moving toward Docker-based sandboxing for the DAST phase. The prompt will be clean: "You are a security tester. Validate these vulnerabilities. Capture evidence." No rules. No skill gates.
This pattern — sandbox-first, prompt-for-quality — is going to become standard as agentic systems mature. We've been through this before in operating systems. The answer has always been the same: enforce safety at the system level, not the application level.